






SourceMap是一种映射关系,用于将压缩后的代码映射回原始的源代码。这在调试压缩后的JavaScript代码时非常有用,因为它允许开发者在浏览器中查看原始的源代码,而不是压缩后的代码。
source-map 的文件格式是JSON文本,文件后缀是 .js.map, 命名一般是js文件后直接添加.map后缀。
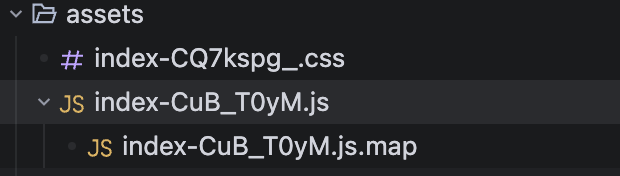
我在代码中主动抛出一个异常,在未使用source-map的情况下,浏览器会直接报错跑出异常的位置,这些代码是编译混淆过的,比较难以理解。
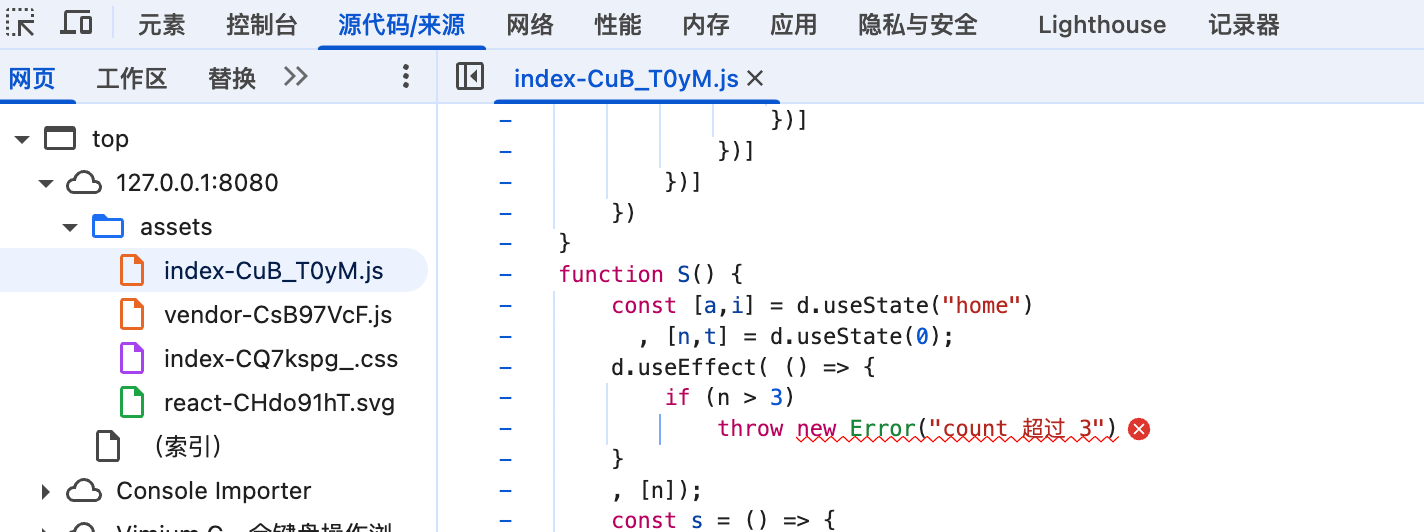
但是在使用source-map的情况下,浏览器会根据source-map映射关系,将异常位置映射到原始的源代码位置,这样开发者就可以直接在原始的源代码中查看异常位置,而不是在混淆后的代码中查看。
source map 原理
用一段最简单的代码来分析下sourcemap的原理,代码如下
function greet(name: string) {
console.log(`Hello, ${name}!`);
}
greet("World");
代码编译后的内容如下
function g(n){console.log("Hello, "+n+"!")}g("World");
//# sourceMappingURL=app.min.js.map
其中最后一行的注释内容就是指向sourcemap的URL路径,格式化后的sourcemap文件如下
{
"version": 3,
"file": "index-CPFZ89nK.js",
"sources": ["../../main.ts"],
"names": ["greet", "name", "console", "log"],
"mappings": "AAAA,SAASA,GAAG,CAACC,EAAS;AACpB,OAAOC,IAAI,GAAG,SAAS,EAAG,CAC1B",
"sourcesContent": [
"function greet(name) {\n console.log(`Hello, ${name}!`);\n}\ngreet(\"World\");"
]
}
可以看到sourcemap文件的主要内容有:
- version:sourcemap 版本
- file:编译后文件名
- sources:源文件路径数组
- sourcesContent:编译前源代码
- names:源代码中变量数组
- mappings:核心部分,Base64-VLQ 编译后的代码位置映射
mappings映射规则
;用于分割编译后的代码行号,即;≈换行。(上述代码打包后只有一行,所以没有分号),用于分词,分隔编译后代码的变量- 英文串标识源码和编译后代码的位置映射,英文串在经过编码之前的内容包含
- 编译后代码所在列
- sources对应的源文件下标(增量)
- 源码的行数(增量)
- 源码的列数(增量)
- names对应的变量下标(增量)
先来复习下编码规则。
Base64 编码
Base64是一种基于64个可打印字符来表示二进制数据的编码方式。这64个字符包括大小写字母、数字和两个特殊符号(通常是’+’和’/‘)。计算过程可以看下我之前的笔记
编码过程:
- 将输入字符串转换为UTF-8编码的二进制数据
- 将二进制数据每3个字节(24位)分为一组
- 将每组24位再分为4个6位的块(因为2^6=64,正好可以用64个字符表示)
- 每个6位块转换为一个0-63的整数,对应Base64字符表中的字符
- 如果最后一组不足3个字节,用0填充并添加相应数量的’=’作为填充符
填充规则:
- 如果原始数据长度能被3整除,不需要填充
- 如果余1,需要添加两个’=’填充符
- 如果余2,需要添加一个’=’填充符
解码过程:
- 移除填充字符’=’
- 将每个Base64字符转换为对应的0-63整数值
- 将4个6位值(共24位)重新组合为3个8位字节
- 将字节数组转换回原始字符串
应用场景:
- 在电子邮件中传输二进制附件
- 在URL中传输二进制数据
- 在HTML中嵌入图片(Data URL)
- 在JSON中传输二进制数据
代码实现
export function base64Encode(str: string): string {
// Base64字符表:A-Z, a-z, 0-9, +, /
const base64Chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// 将字符串转换为UTF-8编码的二进制数据
const bytes = new TextEncoder().encode(str);
let result = '';
// 每次处理3个字节(24位)
for (let i = 0; i < bytes.length; i += 3) {
// 将3个字节合并为一个24位的数字
const byte1 = bytes[i];
const byte2 = i + 1 < bytes.length ? bytes[i + 1] : 0; // 如果不足3字节,用0填充
const byte3 = i + 2 < bytes.length ? bytes[i + 2] : 0; // 如果不足3字节,用0填充
// 将24位分为4个6位的块
const chunk1 = byte1 >> 2; // 取byte1的高6位
const chunk2 = ((byte1 & 0x03) << 4) | (byte2 >> 4); // 取byte1的低2位和byte2的高4位
const chunk3 = ((byte2 & 0x0F) << 2) | (byte3 >> 6); // 取byte2的低4位和byte3的高2位
const chunk4 = byte3 & 0x3F; // 取byte3的低6位
// 将每个6位块转换为Base64字符
result += base64Chars[chunk1];
result += base64Chars[chunk2];
// 处理填充情况
if (i + 1 < bytes.length) {
result += base64Chars[chunk3];
} else {
result += '='; // 添加填充符
}
if (i + 2 < bytes.length) {
result += base64Chars[chunk4];
} else {
result += '='; // 添加填充符
}
}
return result;
}
export function base64Decode(str: string): string {
// Base64字符表:A-Z, a-z, 0-9, +, /
const base64Chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// 创建一个映射表,将Base64字符映射到对应的索引值
const base64Map: Record<string, number> = {};
for (let i = 0; i < base64Chars.length; i++) {
base64Map[base64Chars[i]] = i;
}
// 移除填充字符'='
const cleanStr = str.replace(/=/g, '');
const paddingLength = str.length - cleanStr.length;
// 存储解码后的字节
const bytes: number[] = [];
// 每次处理4个Base64字符(对应3个原始字节)
for (let i = 0; i < cleanStr.length; i += 4) {
// 获取4个Base64字符对应的值
const chunk1 = base64Map[cleanStr[i]] || 0;
const chunk2 = base64Map[cleanStr[i + 1]] || 0;
const chunk3 = i + 2 < cleanStr.length ? base64Map[cleanStr[i + 2]] || 0 : 0;
const chunk4 = i + 3 < cleanStr.length ? base64Map[cleanStr[i + 3]] || 0 : 0;
// 将4个6位值重组为3个8位字节
const byte1 = (chunk1 << 2) | (chunk2 >> 4); // chunk1的6位和chunk2的高2位
const byte2 = ((chunk2 & 0x0F) << 4) | (chunk3 >> 2); // chunk2的低4位和chunk3的高4位
const byte3 = ((chunk3 & 0x03) << 6) | chunk4; // chunk3的低2位和chunk4的6位
// 添加解码后的字节
bytes.push(byte1);
// 根据填充情况决定是否添加后续字节
if (i + 2 < cleanStr.length || paddingLength < 2) {
bytes.push(byte2);
}
if (i + 3 < cleanStr.length || paddingLength < 1) {
bytes.push(byte3);
}
}
// 将字节数组转换为字符串
return new TextDecoder().decode(new Uint8Array(bytes));
}
在线尝试
Base64 VLQ 编码
VLQ (Variable-length quantity) 是一种可变长度编码方式,用于压缩存储整数值,特别是当数值范围很大的时候。VLQ的核心思想是根据数值的大小动态决定使用多少字节来表示。比如小的数字用1个字节,大的数字用多个字节。这种可变长度的设计能有效节省空间。
字节结构
每个 VLQ 字节被分成两部分:
- 最高位(Bit 7,MSB): 延续位(Continuation Bit)。这是最关键的部分。
- 如果该位为 1,表示这个字节不是该数值的最后一个字节,后面还有字节属于同一个数值。
- 如果该位为 0,表示这个字节是该数值的最后一个字节。
- 低 7 位(Bit 6 - Bit 0): 数据位(Data Bits)。这7位用于存储实际数值的一部分。
编码过程(数值 -> VLQ 字节序列):
- 将数字用二进制表示,得到一连串的0和1
- 从右往左数,分别隔成4bit,5bit,5bit,…,最左边的如果不足5个bit则用0补齐
- 对于第一个4bit,如果当前数字是正数,则在后面补一个0,如果是负数则补一个1,得到一个5bit
- 对于所有的5bit串,依次将右边的放到最左边,也就是按5bit为单位,逆序,得到一个新的5bit组
- 对于新的5bit组,最右边的一个5bit在前面加一个0表示后面没有连续的bit了,剩余所有的5bit在前面加一个1表示后面的bit是一个整体,得到一个6bit组
- 用base64对6bit组进行解析,得到一个base64字符串
例如
21的计算过程为:21 -> 10101 -> 1 0101 -> 00001 0101 -> 00001 01010 -> 01010 00001 -> 101010 000001 -> 42 1 -> qB
代码实现
export function vlqEncode(value: number): string {
// 处理符号位:负数需要特殊处理
// 对于负数,先取绝对值,然后将最低位的后一位设为1
// 对于正数,将最低位的后一位设为0
// 这样可以用一个位来表示符号
const signBit = value < 0 ? 1 : 0;
// 取绝对值并左移1位,然后加上符号位
let vlq = (Math.abs(value) << 1) | signBit;
// 用于存储Base64编码结果
let result = '';
// VLQ编码字符集(同Base64,但顺序可能不同)
const vlqChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// 循环处理,直到所有位都被编码
do {
// 取vlq的低5位作为数据位
let digit = vlq & 0x1F; // 0x1F = 31 = 0b11111,取低5位
// 右移5位,为下一次循环准备
vlq >>>= 5;
// 如果还有更多位需要处理,设置连续标志位
if (vlq > 0) {
digit |= 0x20; // 0x20 = 32 = 0b100000,设置第6位为1
}
// 将6位数字映射到Base64字符并添加到结果中
result += vlqChars[digit];
// 显示当前处理状态
console.log(`当前处理: 数据位=${(digit & 0x1F).toString(2).padStart(5, '0')}, 连续位=${(digit & 0x20) >>> 5}, 映射字符='${vlqChars[digit]}'`);
} while (vlq > 0);
return result;
}
export function vlqDecode(encoded: string): number {
// VLQ编码字符集(同Base64,但顺序可能不同)
const vlqChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
let result = 0; // 最终结果
let shift = 0; // 当前位移量
let continuation; // 连续标志位
// 处理每个字符
for (let i = 0; i < encoded.length; i++) {
// 将字符映射到对应的6位值
const charIndex = vlqChars.indexOf(encoded[i]);
if (charIndex === -1) {
throw new Error(`无效的VLQ字符: ${encoded[i]}`);
}
// 提取数据位(低5位)
const digit = charIndex & 0x1F; // 0x1F = 31 = 0b11111
// 提取连续标志位(第6位)
continuation = (charIndex & 0x20) > 0; // 0x20 = 32 = 0b100000
// 将数据位添加到结果中,位置由shift决定
result |= digit << shift;
// 显示当前处理状态
console.log(`解码字符 '${encoded[i]}': 值=${charIndex.toString(2).padStart(6, '0')}, 数据位=${digit.toString(2).padStart(5, '0')}, 连续位=${continuation ? '1' : '0'}, 当前结果=${result.toString(2)}`);
// 如果没有更多组,结束循环
if (!continuation) {
break;
}
// 为下一组准备,每组5位
shift += 5;
}
// 处理符号位
// 最低位为符号标志:1表示负数,0表示正数
const signBit = result & 1;
// 右移一位去除符号位
result >>>= 1;
// 根据符号位还原数值
if (signBit) {
result = -result;
}
return result;
}
应用场景
VLQ 编码(或其变种,如 MIDI VLQ, UTF-8 的部分灵感来源)常用于需要紧凑存储整数序列的场景,尤其是当数值范围未知或小值居多时:
- MIDI 文件格式: 存储音符开始时间(Delta Time),这些时间差通常很小。
- Protocol Buffers (Protobuf): 在其 int32, int64, uint32, uint64, sint32, sint64 等类型的编码中使用了类似 VLQ 的原理(称为 Varint)。
- Base 128 Varints (许多序列化格式): 概念与 VLQ 几乎相同。
- UTF-8 编码: 虽然不是严格的 VLQ,但其使用字节最高位作为状态位(指示字节数和后续字节)的设计思想与 VLQ 的延续位概念有相似之处。
- 某些游戏数据格式或资源文件: 存储偏移量、索引等可能有大范围但小值常见的数据。
可以通过base64vlq网站在线尝试编解码。
sourcemap 生成
按照我们上面的代码示例中的sourcemap文件示例来计算一下mapping的生成过程。
我们上面说过了mapping串的五个组成部分,以greet为例,按照组合方式可列出以下表格
| 编译后所在列 | source文件下标 | 源码行数 | 源码列数 | names下标 | |
|---|---|---|---|---|---|
| 原始位置 | 9 | 0 | 0 | 9 | 0 |
| 编译结果 | S | A | A | S | A |
这就对应了map文件中的SAASA部分。 |


